
Современные приложения должны работать безупречно на разных платформах, таких как iOS, Android и веб. Но синхронизация данных между этими системами — сложная задача. Вот почему:
Платформы, такие как Adalo, конструктор приложений без кода для веб-приложений на основе баз данных и нативных приложений iOS и Android — одна версия для всех трех платформ, публикуемая в Apple App Store и Google Play, помогает решить эти проблемы благодаря унифицированному управлению данными на устройствах из единой среды разработки.
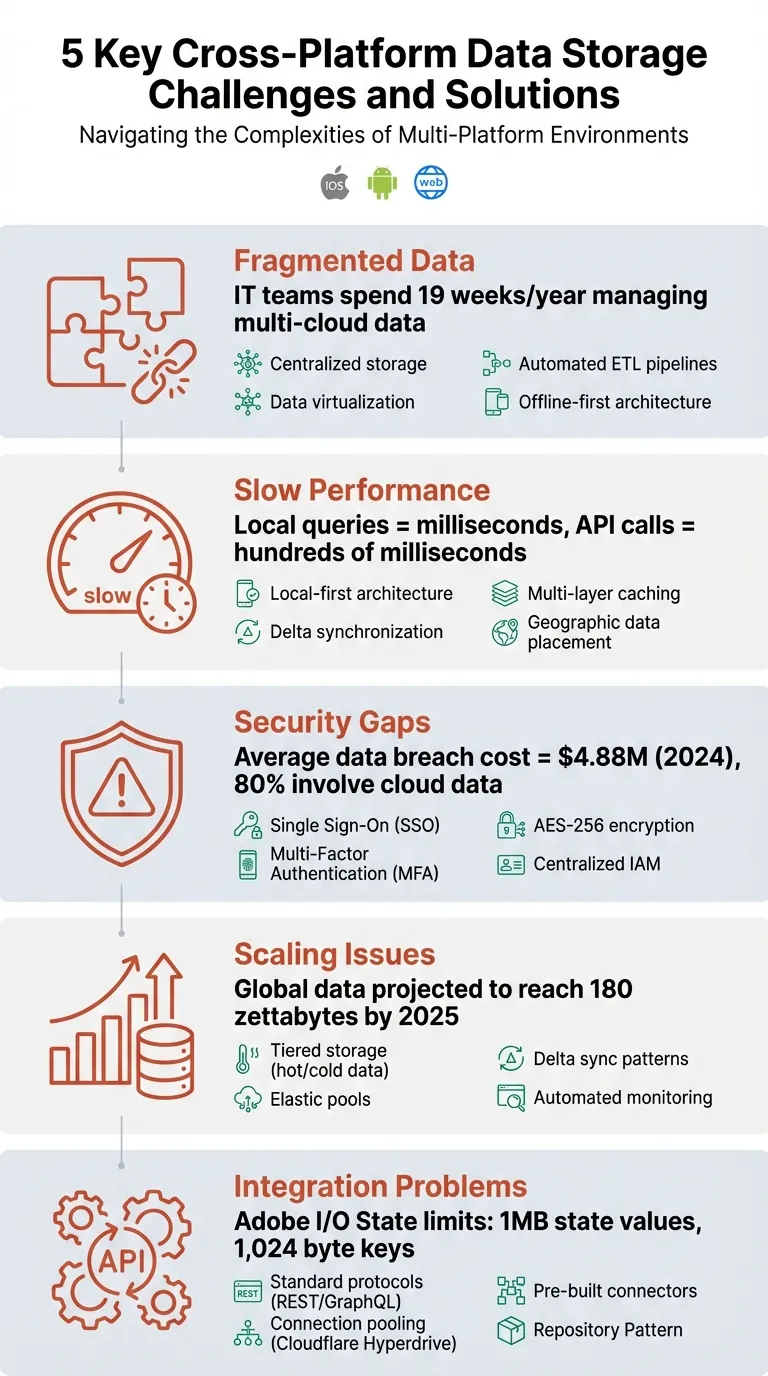
- Фрагментированные данные: отключенные системы создают информационные хранилища, затрудняя синхронизацию информации.
- Медленная производительность: задержки в сети и неэффективные методы синхронизации расстраивают пользователей.
- Бреши в безопасности: несогласованные меры на разных платформах увеличивают риски.
- Проблемы масштабирования: растущий объем данных может перегрузить инфраструктуру.
- Проблемы интеграции: проблемы совместимости между системами замедляют разработку.
Решения включают архитектуру с приоритетом локальной обработки, синхронизацию дельта, унифицированные протоколы безопасности и масштабируемые стратегии хранения. Эти подходы обеспечивают более быструю синхронизацию, лучшую безопасность и более плавную работу между платформами.
5 ключевых проблем хранения данных между платформами и их решения
Проблема 1: фрагментированные данные и отключенные системы
Что такое хранилища данных
Фрагментированные данные на разных платформах создают серьезное препятствие для бесперебойной синхронизации. Хранилища данных появляются, когда различные отделы или платформы хранят информацию без связи между собой. Например, ваша команда продаж может полагаться на одну базу данных, мобильное приложение — на другую, а веб-платформа — на третью, что требует ручного согласования для выравнивания данных.
Устаревшие системы часто не интегрируются с современными облачными инструментами, оставляя изолированные пулы данных. Слияния компаний могут усугубить проблему, объединяя базы данных с несовместимыми структурами. Между тем, отделы, управляющие своими данными независимо, усиливают фрагментацию. В отраслях, таких как здравоохранение, эти отключенные данные могут стоить десятки и сотни миллиардов долларов в год, в то время как команды ИТ тратят в среднем 19 недель в год на управление данными в нескольких общедоступных облачных средах.
Решения: подключение ваших данных
Разрушение этих хранилищ начинается с интеграции данных из различных источников в единую систему. Один эффективный подход — централизованная архитектура хранилища, которая создает единый источник истины. Озера данных идеальны для консолидации сырых неструктурированных данных из нескольких источников, а хранилища данных лучше подходят для управления структурированными данными, используемыми в конкретных анализах. Для дополнительной гибкости, озера-хранилища данных сочетают сильные стороны обоих подходов, позволяя управлять структурированными и неструктурированными данными в одной системе.
Еще одно решение — виртуализация данных. Инструменты, такие как Denodo и Cisco , позволяют получить унифицированное представление данных на платформах, таких как AWS, Azure, и Google Cloud , без физического перемещения данных. Это особенно полезно для анализа в реальном времени, когда необходимо сохранять данные в их исходном местоположении.
Для организаций, готовых к консолидации, автоматизированные конвейеры ETL упрощают этот процесс. Инструменты, такие как Talend или Stitch Data , могут передавать и преобразовывать данные из разнородных систем в централизованное хранилище. Сохранение данных в совместимых форматах, таких как Apache Parquet или Avro , обеспечивает совместимость с инструментами аналитики и облачными платформами.
Кроссплатформенные приложения могут значительно выиграть от архитектуры с приоритетом автономной работы, которая кэширует данные локально и синхронизируется с облаком при восстановлении подключения. Это гарантирует, что пользователи имеют доступ к информации даже при плохих условиях сети, улучшая синхронизацию данных на iOS, Android и веб-платформах одновременно.
Проблема 2: медленная производительность и задержки
Что вызывает задержки между платформами
Когда системы фрагментированы, обеспечение быстрых передач данных становится важным для предотвращения вялой работы между платформами. Главный виновник задержек — модели данных, зависящие от сервера, которые требуют, чтобы приложения ждали ответов сервера перед отображением информации. В то время как локальные запросы можно выполнить всего за несколько миллисекунд, сетевые вызовы могут занять сотни — особенно когда серверы находятся далеко от пользователей или когда условия сети плохие. Архитектор мобильных приложений Sudhir Mangla описывает эту досадную ситуацию как Lie-Fi — ситуации, когда устройства указывают на сильный сигнал, но страдают от низкой пропускной способности, непредсказуемых скачков задержки или потери пакетов.
Неэффективные методы синхронизации также играют определенную роль. Подходы полной синхронизации, например, часто отбрасывают локальные данные для перезагрузки всех наборов данных, что приводит к потере времени и ресурсов. Аналогично, ограничения частоты запросов сторонних API могут требовать нескольких циклов для импорта больших наборов данных, что еще больше замедляет процесс.
«Даже когда сеть стабильна, получение данных локально всегда быстрее, чем обращение к серверу туда и обратно. Запрос к локальной базе данных может вернуть результаты за миллисекунды; вызов API может занять сотни миллисекунд.» - Суджир Мангла, мобильный архитектор
«Поэтому offline-first — это не только стратегия отказоустойчивости, но и стратегия производительности.»
Эти проблемы указывают на необходимость переосмысления того, как передаются и управляются данные.
Решения: более быстрая передача данных
Комбинация архитектуры, ориентированной на локальные данные, и дельта-синхронизацией может значительно улучшить производительность. Используя локальную базу данных — такую как Room, Realmили SQLite — в качестве основного хранилища данных, приложения могут мгновенно обрабатывать взаимодействия пользователя. Механизм синхронизации в фоновом режиме может затем управлять обновлениями данных, обмениваясь только измененными записями, используя управляемые сервером токены синхронизации для предотвращения проблем со смещением часов.
Для дополнительного ускорения внедрите многоуровневое кэширование для ответов API, запросов к базе данных и статических ресурсов, обеспечив быстрое получение часто используемых данных. Разместите хранилища данных в том же географическом регионе, что и компоненты вашего приложения, чтобы снизить задержку и избежать дополнительных затрат на пропускную способность между регионами. Менеджеры фоновых задач могут управлять процессами синхронизации без прерывания взаимодействия пользователя, в то время как оптимистичные обновления позволяют пользовательскому интерфейсу отражать изменения немедленно, синхронизируя в фоновом режиме для завершения обновлений.
Эти стратегии не только устраняют задержки, но и создают более плавный и отзывчивый пользовательский опыт.
Проблема 3: проблемы безопасности и управления доступом
Риски несогласованной безопасности
Когда практики безопасности различаются на разных платформах, таких как iOS, Android и веб, возникают уязвимости. В 2026 году средняя стоимость утечки данных составила 4,88 миллиона долларов, при этом около 80% нарушений связаны с данными, хранящимися в облаке. Это подчеркивает серьезные деловые риски несогласованных мер безопасности.
Одна из главных проблем — утечка данных между тенантами в общей инфраструктуре. Без надежной аутентификации и авторизации, один тенант может случайно получить доступ к данным другого в общих базах данных или контейнерах больших двоичных объектов. В качестве дополнительной проблемы, облачные провайдеры часто используют различные параметры по умолчанию и протоколы шифрования, создавая слабые места, которые могут использовать злоумышленники. Ручные процессы, такие как отслеживание изменений схемы или применение патчей в нескольких базах данных, еще больше увеличивают вероятность ошибок и брешей в безопасности.
Другая проблема заключается в внедрении детальных средств управления, таких как безопасность на уровне строк. Без правильного проектирования и тестирования эти элементы управления могут оставить поддающиеся эксплуатации бреши. В системах асинхронной репликации одновременные обновления в разных местоположениях могут привести к несогласованным состояниям данных, потенциально обходя ограничения безопасности, если разрешение конфликтов обработано неправильно.
Решение? Единая стратегия безопасности, которая работает беспрепятственно на всех платформах.
Решения: единые системы безопасности
Для решения этих проблем необходим консолидированный подход к безопасности. Начните с решений для единого входа (SSO) использования протоколов, таких как аутентификацию OAuth 2.0 или SAML. Это гарантирует согласованные политики безопасности на всех платформах — будь то iOS, Android или веб. Объедините это с централизованным управлением идентификацией и доступом (IAM) для обеспечения принципа наименьших привилегий, ограничивая доступ пользователя только тем, что необходимо для их ролей.
многофакторную аутентификацию (MFA) — еще один критически важный уровень защиты. Поскольку фишинг и украденные учетные данные являются основными методами атак в 2026 году, многофакторная аутентификация значительно снижает риск. Объедините это со стандартизированными протоколами шифрования, такими как AES-256 для данных в состоянии покоя и TLS для данных в пути, чтобы установить надежную защиту во всей вашей инфраструктуре.
Вот как единый подход упрощает безопасность:
| Функция безопасности | специфичная для платформы проблема | единое преимущество |
|---|---|---|
| Аутентификация | различные биометрические API (FaceID vs. Android Biometrics) | централизованная многофакторная аутентификация/единый вход обеспечивает согласованный опыт входа |
| управление доступом | несогласованная обработка разрешений в разных версиях ОС | управление доступом на основе ролей (RBAC) стандартизирует разрешения на всех устройствах |
| Управление сеансами | различные хранилища токенов (Keychain vs. Keystore) | единое управление токенами упрощает логику истечения срока и обновления |
| хранение данных | различные стандарты шифрования для каждой платформы | стандартизированное шифрование (AES-256) защищает данные на всех платформах |
для еще большей безопасности рассмотрите возможность использования шифрования на уровне тенанта с использованием инструментов, таких как «Always Encrypted» или управляемых клиентом ключей (CMK). Они обеспечивают защиту данных даже в общей среде хранения. Паттерн Valet Key это еще один эффективный метод, обеспечивающий безопасный доступ с ограничением по времени к ресурсам хранилища на разных платформах. Кроме того, хранение конфиденциальных учетных данных и ключей API в специальных инструментах управления секретами — вместо их встраивания в код — обеспечивает дополнительный уровень защиты.
Автоматизация — ключ к снижению человеческих ошибок. Автоматизируйте изменения схемы, конфигурации безопасности и регулярные аудиты IAM, чтобы сохранить надежный уровень безопасности. Для межплатформенного взаимодействия используйте взаимные TLS-сертификаты (mTLS) для аутентификации сервисов и обеспечения безопасной передачи данных в облачных средах.
Вызов 4: масштабирование и управление затратами
Как рост данных влияет на инфраструктуру
Данные растут с поразительной скоростью. К 2026 году глобальный объем данных прогнозируется на уровне 180 зеттабайт, при этом многие современные системы генерируют терабайты или даже петабайты данных каждый день. Для кроссплатформенных приложений этот всплеск данных происходит из двух источников: увеличение объема данных, генерируемых на одного клиента, и постоянно расширяющаяся базе клиентов.
Справиться с этим взрывом данных непросто. Традиционные базы данных часто не могут справиться с таким масштабом. В средах совместной инфраструктуры проблема «шумного соседа» — когда интенсивное использование одним клиентом замедляет производительность для всех остальных — может еще больше усложнить ситуацию. Когда вы управляете 50 и более клиентами, ручное управление становится практически невозможным, и автоматизированные инструменты масштабирования становятся необходимостью.
«Рассматривайте данные как самый ценный актив вашего решения. Как независимый поставщик программного обеспечения (ISV), вы несете ответственность за управление данными своих клиентов. Ваша стратегия проектирования данных и выбор хранилища данных могут значительно повлиять на ваших клиентов.»
– Microsoft Azure Well-Architected Framework
Без четкого плана вы рискуете либо избыточным подготовлением ресурсов — потратить деньги на неиспользуемые ресурсы — либо недостаточным подготовлением, что приводит к ограничению запросов и недовольству пользователей. В многоклиентных средах учетные записи хранилища, превышающие лимиты операций в секунду, могут начать отклонять запросы, нарушая работу сервиса для всех пользователей.
Эффективное решение этих проблем требует стратегического подхода, который балансирует производительность и экономическую эффективность.
Решения: многоуровневое хранилище и контроль затрат
Чтобы справиться с растущими объемами данных без превышения бюджета, вам нужна комбинация умных стратегий. Опираясь на меры производительности и безопасности, обсуждавшиеся ранее, контроль затрат становится последним компонентом для бесперебойной кроссплатформенной работы.
Начните с выравнивания своего подхода к хранилищу с фактическими моделями использования. Многоуровневое хранилище — отличный способ оптимизировать затраты. Часто используемые «горячие» данные могут оставаться на высокопроизводительных SSD, в то время как менее используемые данные переходят на более доступные варианты, такие как объектное хранилище или архивные уровни. Этот метод значительно сокращает расходы при сохранении скорости для активных пользователей.
Планирование емкости — еще один критический этап. Использование модели «размер по типу» — разделение клиентов на категории малые, средние или большие — помогает спрогнозировать потребности в ресурсах и согласовать их с соответствующими структурами биллинга. Объедините это с управлением жизненным циклом данных, которое автоматизирует хранение данных. Например, базы данных, такие как Azure Cosmos DB , предлагают функции Time-to-Live (TTL) для автоматического удаления устаревших записей, сохраняя вашу основную базу данных оптимизированной.
Для рабочих нагрузок с непредсказуемыми всплесками пулы эластичности и модели общей пропускной способности позволяют нескольким базам данных совместно использовать один пул ресурсов. Бессерверные модели, которые автоматически масштабируются в зависимости от спроса, — еще один вариант, но они могут стать менее экономичными при масштабировании использования.
Чтобы дополнительно сократить затраты в многоклиентных средах, применяйте паттерны дельта-синхронизации. Они снижают требования к полосе пропускания и серверу, синхронизируя только изменения вместо всего набора данных. Например, Cloudflare's D1 SQL database использует меньшие базы данных по 10 ГБ, организованные по пользователю или клиенту для эффективного масштабирования.
Мониторинг также критичен. Отслеживайте ограничения, контролируя отклоненные операции хранилища, чтобы убедиться, что совместные учетные записи остаются в пределах лимитов. Автоматизация задач, таких как перестроение индексов и переоптимизация разделов, также может снизить необходимость в ручном вмешательстве, экономя время и деньги.
| Стратегия | Лучше всего подходит для | Влияние на затраты |
|---|---|---|
| Пулы эластичности | Небольшие/средние базы данных с переменными пиками спроса | Высокая эффективность; снижает затраты на неиспользуемые ресурсы |
| Бессерверные | Новые приложения или низкочастотные, непредсказуемые рабочие нагрузки | Оплата по мере использования; может быть дорогостоящим при больших объемах |
| Архивное хранилище | Долгосрочное соответствие и исторические данные | Самая низкая стоимость; более медленное время извлечения |
| Дельта-синхронизация | Мобильные/кроссплатформенные приложения | Снижает расходы на полосу пропускания и сервер |
Вызов 5: Проблемы интеграции и совместимости
Распространенные барьеры интеграции
Связывание систем хранения данных между платформами не так просто, как может показаться. Одним из основных препятствий является несовместимость библиотек, которая часто заставляет разработчиков поддерживать отдельные кодовые базы для мобильных и веб-приложений. Даже если системы используют одну и ту же структуру данных, несоответствия в том, как разные операционные системы и браузеры обрабатывают JSON, могут привести к непредсказуемому поведению приложения.
Еще одна проблема — задержка соединения, особенно в бессерверных средах. Традиционные базы данных SQL зависят от сокетов TCP, которые требуют нескольких туров приема-передачи для установления безопасных соединений. В бессерверных или пограничных средах вычисления эти соединения должны переустанавливаться с каждым вызовом, добавляя заметные задержки. Эта проблема усугубляется географическим расстоянием — серверы, расположенные, например, в США, могут вызывать задержки для пользователей в других частях мира.
Облачные решения для хранения данных имеют собственный набор ограничений. Например, простые хранилища типа ключ-значение, такие как Adobe I/O State , не имеют необходимых функций запроса, таких как фильтрация строк, выбор определенных столбцов или ограничение результатов. Разработчики, привыкшие к традиционным базам данных, часто не хватает этих возможностей. Кроме того, Adobe I/O State ограничивает значения состояния 1 МБ и размеры ключей до 1024 байтов, что может быть ограничивающим для некоторых случаев использования. Эти вызовы подчеркивают острую необходимость в стандартизированных протоколах для упрощения кроссплатформной интеграции.
Решения: стандартные протоколы и готовые к использованию соединители
Стандартизированные протоколы и платформы со встроенными соединителями предлагают практический способ решения проблем интеграции. Инструменты, такие как Cloudflare Hyperdrive , решают проблемы задержки за счет объединения подключений к базам данных на глобальном уровне, устраняя задержки, вызванные повторными рукопожатиями TCP. Для систем без встроенных соединителей, REST API или интерфейсы GraphQL обеспечивают мост, обеспечивая совместимость между платформами. Между тем, инструменты, такие как Adobe I/O State, предлагают абстракции JavaScript на основе распределенных баз данных, позволяя разработчикам управлять сохранением состояния без погружения в сложные облачные конфигурации.
Платформы, такие как Adalo упрощают интеграцию дальше, предлагая предварительно построенные соединители для популярных сторонних сервисов, включая Airtable, Google Sheets, MS SQL Server, и PostgreSQL. Эти готовые интеграции снижают необходимость в обширном кодировании на стороне сервера. Для устаревших систем без API, Adalo Blue использует DreamFactory для упрощения соединений.
Еще один эффективный подход — Паттерн репозитория, который создает четкую границу между слоем пользовательского интерфейса и слоем хранилища. Эта абстракция скрывает, хранятся ли данные локально (например, SQLite или Realm) или удаленно через облачные API, что упрощает поддержку кроссплатформного кода. Разработчики также могут использовать расширения файлов, специфичные для платформы, такие как index.web.js и index.ios.js , чтобы убедиться, что правильный код запускается на каждой платформе автоматически. Для повышения безопасности всегда защищайте конфиденциальные учетные данные, такие как ключи API и пароли баз данных, с помощью секретов окружения. Инструменты, такие как Wrangler secrets, позволяют безопасно внедрить эти учетные данные во время выполнения.
Узнайте, как создавать приложения с кроссплатформным хранилищем данных в сетевом режиме и в режиме без сети менее чем за 30 минут
Как реализовать эти решения
Решение проблем кроссплатформного хранения данных требует хорошо продуманного подхода. Вот как вы можете применить эти решения на практике.
Разделение крупных миграций
При перемещении данных пошаговый подход — более разумный выбор. Вместо того чтобы переместить все сразу, рассмотрите поэтапную миграцию , также называемую постепенной миграцией. Этот метод передает данные небольшими порциями, позволяя старой и новой системам работать рядом. Преимущество? Минимальное время простоя и текущее тестирование, что идеально подходит для критичных систем. Например, компания успешно перевела свою систему платежей в реальном времени без каких-либо перерывов, следуя этому подходу.
Другой вариант — стратегия параллельной миграции, где обе системы работают одновременно с синхронизацией. Трафик перенаправляется на новую систему только после того, как она полностью протестирована и проверена. Обе стратегии избегают рисков миграции «с нуля», которая может привести к длительному времени простоя или серьезным сбоям при возникновении проблем.
После завершения миграции постоянный мониторинг необходим для поддержания производительности и обеспечения стабильности.
Мониторинг и улучшение систем данных
После того как ваше кроссплатформное хранилище включено и работает, важно следить за его производительностью. Используйте такие метрики, как байты в секунду (B/s) или транзакции в секунду (TPS) для отслеживания того, насколько хорошо работает система. Даже небольшие изменения в запросах могут заметно повлиять на скорость, поэтому регулярные оценки производительности имеют решающее значение. Мониторинг пропускной способности помогает выявить узкие места до того, как они повлияют на пользователей.
«Каждый раз, когда ваше приложение запрашивает базу данных... производительность приложения будет страдать. Поэтому критически важно всегда помнить о производительности при разработке.» — Ресурсы Adalo
Автоматизация рутинных задач может сэкономить время и улучшить здоровье системы. Задачи, такие как перестройка индексов, перебалансировка разделов и мониторинг объема данных, должны быть автоматизированы везде, где это возможно. Следите за дросселированием и регулярно оптимизируйте производительность, чтобы все работало гладко.
По мере роста пользовательской базы и данных масштабируемая платформа становится необходимой для поддержания стабильной производительности.
Использование масштабируемых платформ
Платформа, построенная на едином кодовом базе, может значительно упростить поддержку кроссплатформенности. Adalo, например, использует архитектуру с единой кодовой базой, которая упрощает разработку для мобильных и веб-приложений. Обновления, сделанные один раз, автоматически применяются на платформах iOS, Android и web.
Такой единый подход не только снижает фрагментацию, но и ускоряет развертывание. Команды могут выпустить приложения, готовые к производству, всего за дни или недели, в отличие от месяцев, обычно требуемых для специально созданных решений.
Заключение
Управление кроссплатформным хранилищем данных сопряжено с множеством проблем — фрагментированные системы, замедление производительности, уязвимости безопасности и проблемы масштабирования. Решение этих проблем требует унифицированных решений, которые хорошо спланированы, безопасны и способны расти вместе с вашими потребностями.
Лидеры отрасли последовательно подчеркивают важность данных в любом решении:
«Данные часто считаются наиболее ценной частью решения, потому что они представляют вашу и ценную деловую информацию ваших клиентов.»
– Джон Даунс, главный инженер-программист, Microsoft
При управлении операциями для дюжин клиентов автоматизация становится обязательным инструментом. Она обеспечивает беспрепятственный рост без упирания в потолок мощности. Как исследуется в этой статье, успех заключается в принятии единой стратегии — такой, которая интегрирует разработку, развертывание и безопасность в согласованную платформу. Относитесь к вашим данным как к самому критичному активу, используя управляемые сервисы, стандартизированные методологии и архитектуры с единой базой кода, чтобы снизить риски и поддерживать стабильную производительность на разных платформах. Такие шаги, как поэтапные миграции, активный мониторинг и автоматическое обслуживание, обеспечивают надежную основу для эффективных и масштабируемых операций.
Похожие посты в блоге
- Автономная синхронизация в сравнении с синхронизацией в реальном времени: управление конфликтами данных
- Синхронизация на основе событий для приложений, работающих в режиме offline-first
- Как синхронизировать данные между веб-приложениями и мобильными приложениями
- Синхронизация ERP в реальном времени с унаследованными системами
Часто задаваемые вопросы
Как архитектура, ориентированная на локальные данные, улучшает синхронизацию данных между платформами?
Архитектура, ориентированная на локальные данные, сосредоточена на хранении и обработке данных непосредственно на устройстве пользователя, обеспечивая беспрепятственный опыт даже при отсутствии подключения к интернету. Этот подход гарантирует, что пользователи могут получать доступ к информации и обновлять её без перебоев, что особенно полезно в регионах с плохим или ненадежным сетевым подключением. Кроме того, обрабатывая большинство операций на устройстве, приложения становятся более отзывчивыми с сокращенными задержками, вызванными общением с сервером.
Когда соединение восстанавливается, система автоматически синхронизирует изменения, сделанные локально, с удаленными базами данных, обеспечивая согласованность данных на всех устройствах и платформах. Этот процесс синхронизации часто включает обнаружение и разрешение конфликтов для поддержания точности данных. Синхронизируя только при необходимости, архитектура, ориентированная на локальные данные, экономит сетевые ресурсы, снижает нагрузку на сервер и масштабируется эффективно. Это делает её умным выбором для приложений, предназначенных для использования на нескольких устройствах, обеспечивая более быстрый и надежный опыт в условиях неидеального сетевого подключения.
Какие лучшие способы защитить данные на разных платформах?
Защита данных на разных платформах требует комбинации стратегий, чтобы сохранить их в безопасности и доступности. Ключевым шагом является шифрование данных в состоянии покоя и при передаче. Это обеспечивает защиту чувствительной информации, особенно когда она передается между платформами или облачными средами.
Еще одна критичная мера — установка надежных элементов управления доступом. Инструменты, такие как решений для единого входа (SSO) и разрешения на основе ролей ограничивают доступ только авторизованным пользователям. Сочетайте их с безопасными протоколами аутентификации и системами управления удостоверениями, чтобы добавить дополнительный уровень защиты.
Чтобы повысить как безопасность, так и производительность, уточните управление данными. Упростите запросы, используйте кеширование для сокращения времени загрузки и примите шаблоны синхронизации в режиме оффлайн в первую очередь, чтобы обеспечить согласованность данных даже при ненадежном сетевом подключении. Эти шаги не только улучшают пользовательский опыт, но и минимизируют потенциальные риски, связанные с устаревшими или несинхронизированными данными. Вместе эти стратегии создают надежную платформу для защиты данных на всех платформах.
Что такое многоуровневое хранилище и как оно снижает затраты на хранение данных между платформами?
Многоуровневое хранилище предлагает разумный способ управления данными на платформах путем их организации на основе частоты использования. Данные, которые часто используются, хранятся на высокоскоростном, премиум-хранилище, а менее используемые данные переносятся на более медленные, экономичные варианты.
Этот метод достигает баланса между производительностью и стоимостью. Он обеспечивает бесперебойную работу критичных задач при управляемых затратах на хранение. Сопоставляя решения для хранилища с использованием данных, предприятия могут сэкономить деньги без компромисса в отношении эффективности или потенциала роста.
Быстро создавайте приложение с помощью одного из наших готовых шаблонов приложений
Начните создавать без кодаСвязанный контент
Контрольный список для кроссплатформенного тестирования приложений
Контрольный список для кроссплатформенного тестирования приложений
Практический контрольный список для тестирования кроссплатформенных приложений на iOS, Android, веб и PWAs — охватывает функциональность, UI/UX, производительность, безопасность, уст
Лучший кроссплатформенный конструктор ИИ-приложений в 2026
Лучший кроссплатформенный конструктор ИИ-приложений в 2026
Сравните лучшие конструкторы ИИ-приложений для кроссплатформы в 2026. Независимые данные из 345 открытых источников. Найдите, какие платформы поставляют на iOS, Android и веб из одного проекта.

Лучшие практики развертывания кроссплатформенных приложений
Развертывайте приложения по веб-сайтам, iOS и Android из одной кодовой базы: используйте CI/CD, кроссплатформенное тестирование и оптимизации, зависящие от платформы, чтобы сэкономить в

Полное руководство по кроссплатформенному развертыванию приложений
Создавайте, публикуйте и поддерживайте приложения для iOS, Android и веб из одной кодовой базы — сравните нативные, гибридные и PWAs, оптимизируйте производительность и следуйте