
Улучшение времени отклика API при работе с устаревшими базами данных заключается в устранении распространённых узких мест, таких как медленные запросы, устаревшая инфраструктура и неэффективная выборка данных. Эти системы часто сталкиваются с проблемами высокой задержки, проблемами запросов N+1 и отсутствием индексов, что может привести к разочарованию пользователей и замедлению операций.
Платформы, такие как Adalo, конструктор приложений без кода для веб-приложений на основе баз данных и нативных приложений iOS и Android — одна версия для всех трёх платформ, опубликованная в Apple App Store и Google Play, предлагает практическое решение для команд, желающих модернизировать свой подход. Позволяя разработчикам создавать современные интерфейсы, которые подключаются к существующей инфраструктуре баз данных, эти инструменты помогают закрыть разрыв между унаследованными системами и современными ожиданиями пользователей.
Ключевые выводы:
- Оптимизация запросов: Используйте инструменты, такие как
EXPLAIN ANALYZE(PostgreSQL) или журналы медленных запросов (MySQL) для выявления неэффективностей. Исправляйте проблемы N+1 запросов с помощью нетерпеливой загрузки и оптимизируйте соединения для снижения затрат. - Индексирование: Добавляйте индексы для ускорения
WHERE,JOIN, иORDER BYопераций. Составные индексы эффективно обрабатывают многоколоночную фильтрацию. - Кэширование: инструменты наподобие Redis или Memcached сокращают повторяющиеся обращения к базе данных, улучшая время отклика для API с интенсивным чтением.
- Пул соединений: Переиспользуйте соединения с базой данных для снижения задержки, особенно в установках с высокой параллелизацией.
- Пакетизация: Консолидируйте несколько операций чтения или записи в отдельные транзакции для экономии ресурсов.
Воздействие в реальном мире:
Переход с локальной SQLite базы данных на размещённую в облаке устаревшую базу данных увеличил время запросов с 500 мс до 4 секунд для 200 запросов. Однако методы, такие как кэширование и пул соединений, сократили время отклика на 96%.
Решения в действии:
Платформы, такие как DreamFactory может преобразовать устаревшие базы данных в REST API, упрощая интеграцию и повышая производительность. Сочетание этого с инструментами, такими как Adalo позволяет командам создавать современные приложения, которые беспрепятственно подключаются к унаследованным системам без переработки бэкенда.
Сосредоточившись на этих оптимизациях, вы можете значительно улучшить производительность API, расширяя применимость устаревших баз данных.
Лучшие практики производительности REST API
Поиск узких мест производительности в интеграциях API
Выявление узких мест — критический первый шаг в решении проблем медленного времени отклика, вызванных устаревшими базами данных. Чтобы улучшить производительность API, вам необходимо точно определить, где возникают задержки. Запросы к базе данных следуют чёткой последовательности: анализ, выполнение и упаковка данных. Узкие места могут возникнуть на любом из этих этапов, но диагностика их в унаследованных системах особенно сложна из-за устаревших инструментов, которым не хватает современных возможностей наблюдаемости.
Понимание этих проблем создаёт основу для целенаправленной оптимизации, которая может значительно сократить время отклика.
Использование инструментов профилирования для анализа производительности
Большинство основных баз данных включают инструменты профилирования, которые помогают выявить внутренние неэффективности. Вот как их эффективно использовать:
- PostgreSQL: используйте
EXPLAIN ANALYZEдля просмотра как предполагаемого, так и фактического времени выполнения, что позволяет проводить точную настройку запросов. - MySQL: Активируйте журнал медленных запросов для фиксации запросов, выполняемых дольше 500 мс, что помогает изолировать узкие места.
- SQL Server: Средство просмотра плана выполнения в SQL Server Management Studio выделяет ресурсоёмкие операции, а Azure SQL пользователи могут использовать
sys.query_store_wait_statsдля мониторинга времени ожидания, вызванного ограничениями ресурсов, блокировкой или проблемами с памятью.
При профилировании сосредоточьтесь на трёх ключевых метриках: задержка (время туда и обратно), пропускная способность (обработанные запросы за определённый период времени) и время отклика (общее время от запроса к ответу). Обратите пристальное внимание на соотношение просканированных строк к возвращённым строкам — высокое соотношение часто указывает на отсутствие индексов, что приводит к неэффективной выборке данных.
После сбора этих метрик следующий шаг — исключение избыточных запросов и оптимизация соединений для повышения производительности.
Выявление проблем N+1 запросов и неэффективных соединений
Проблема N+1 запросов — это печально известный источник утечек производительности в интеграциях API. Она возникает, когда API извлекает список N записей, а затем выполняет N дополнительных запросов для получения связанных данных для каждой записи. Эта проблема особенно распространена в GraphQL реализациях, где каждый распознавательный механизм поля выполняет отдельный запрос, что затрудняет обнаружение проблемы.
Для выявления проблем N+1 ищите схемы, где одному начальному запросу следуют дюжины — или даже сотни — дополнительных запросов. То, что должно быть одним обращением к базе данных, может быстро превратиться в серьёзное узкое место производительности.
Операции соединения являются еще одним частым источником неэффективности. Чтобы избежать проблем, ограничьте объединения тремя или четырьмя таблицами в одном запросе; более глубокие объединения требуют экспоненциально больше ресурсов. Когда возможно, используйте INNER JOIN вместо LEFT JOIN, так как первый вариант обычно быстрее при гарантированной ссылочной целостности.
Для рабочих нагрузок с интенсивным чтением и сложной агрегацией рассмотрите использование материализованных представлений. Они предварительно вычисляют результаты в непиковые часы, снижая нагрузку в периоды высокого трафика. Вместе эти стратегии помогают преодолеть типичные проблемы и повысить производительность устаревших баз данных.
Повышение производительности API с помощью оптимизации запросов и кэширования
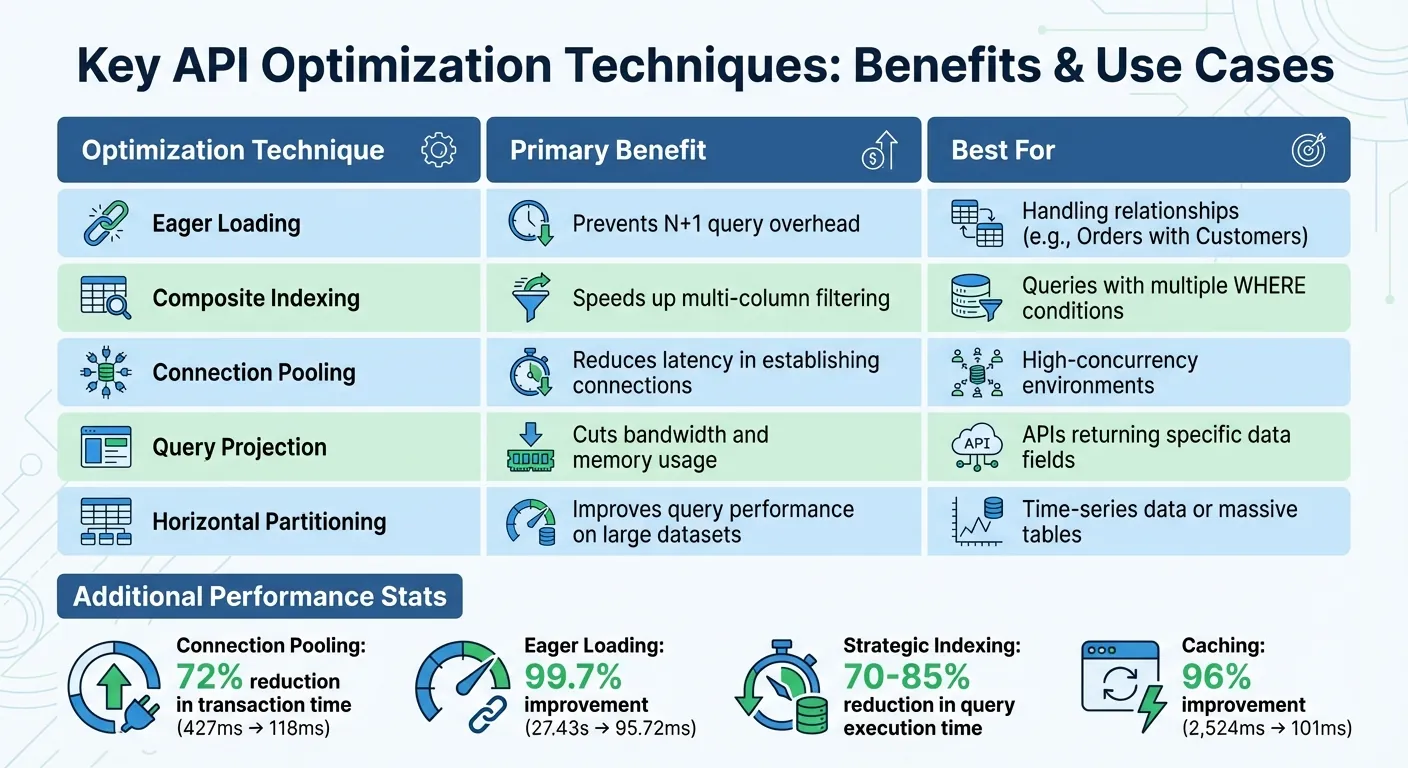
Методы оптимизации производительности API и их влияние на время отклика
После выявления узких мест точная настройка запросов и реализация стратегий кэширования могут значительно улучшить время отклика API. Вот как эффективно решить эти проблемы.
Исправление запросов N+1 с помощью упреждающей загрузки
Проблема запроса N+1 возникает, когда приложение выполняет один запрос для получения списка элементов, а затем дополнительные запросы для связанных данных, по одному для каждого элемента. Упреждающая загрузка решает эту проблему, получив все необходимые данные в одной поездке в базу данных. Методы, такие как JOINs или пакетная обработка (например, WHERE id IN (...)) могут объединить несколько запросов в один.
Например, Laravel API улучшил время отклика с 27,43 секунды до всего лишь 95,72 мс за счет сокращения более 4400 запросов до 10 с помощью упреждающей загрузки и индексирования.
Большинство современных ORM предоставляют встроенную поддержку упреждающей загрузки. В Laravel вы можете использовать with() метод для предварительной загрузки связей, в то время как Django предлагает select_related() для эффективной загрузки связанных данных. Цель — получить все необходимые данные заранее, избегая повторяющихся запросов при итерации.
Использование индексов и фильтров для снижения затрат на запросы
Стратегическое использование индексов может сократить время выполнения запроса на 70–85%. Индексируйте столбцы, используемые в WHERE, JOIN, и ORDER BY условиях для ускорения поиска. Составные индексы особенно полезны при фильтрации по нескольким столбцам. Такие инструменты, как EXPLAIN ANALYZE могут помочь определить, какие запросы больше всего выигрют от индексирования.
Помимо индексирования, проекция запроса — выбор только нужных столбцов вместо использования SELECT *— может значительно сократить объем обрабатываемых и передаваемых данных, особенно при работе с устаревшими таблицами, содержащими множество столбцов.
Подготовленные инструкции также играют роль благодаря предварительной компиляции запросов, что сокращает время синтаксического анализа и повышает безопасность. Другая эффективная тактика — пакетировка нескольких операций чтения или записи в одну транзакцию, что может улучшить время отклика на столько же, насколько 45%.
Эти оптимизации создают основу для еще больших улучшений производительности за счет кэширования и объединения соединений.
Добавление кэширования и объединения соединений
Кэширование может резко снизить нагрузку на базу данных, особенно для API с интенсивным чтением. Такие инструменты, как Redis или Memcached, хранят часто используемые результаты запросов в памяти, исключая избыточные обращения к базе данных для стабильных данных, таких как профили пользователей или справочные таблицы. Чтобы сохранить точность кэша, реализуйте логику инвалидации для обновления записей при изменении базовых данных (например, после запросов POST или PUT).
Объединение соединений снижает затраты на создание новых TCP/TLS соединений для каждого запроса API. Благодаря повторному использованию постоянных соединений время транзакции может сократиться на столько же, насколько 72%— например, с 427 мс до 118 мс в сценариях с высокой параллелизмом. В одном случае повторное использование соединений в Django ускорило время отклика API в 8–9 раз.
Специализированные инструменты, такие как HikariCP для Java или PgBouncer и ProxySQL для PostgreSQL и MySQL могут помочь эффективно управлять объединением соединений. В бессерверных установках повторное использование клиентов баз данных при несколько вызовов может предотвратить перегрузку пула соединений.
Вот сводка ключевых методов оптимизации и их преимуществ:
| Методика оптимизации | Основное преимущество | Лучше всего подходит для |
|---|---|---|
| Упреждающая загрузка | Предотвращает затраты на запросы N+1 | Обработка связей (например, заказы с клиентами) |
| Составное индексирование | Ускоряет фильтрацию по нескольким столбцам | Запросы с несколькими WHERE условиями |
| Пул соединений | Снижает задержку при установлении соединений | Среды с высокой параллелизмом |
| Проекция запроса | Снижает использование пропускной способности и памяти | API, возвращающие определённые поля данных |
| Горизонтальное секционирование | Повышает производительность запросов на больших наборах данных | Данные временных рядов или огромные таблицы |
Комбинирование этих методов часто дает лучшие результаты. Например, сочетание упреждающей загрузки с кешированием может оптимизировать как начальное извлечение данных, так и последующие запросы, а пулинг соединений обеспечивает способность системы обрабатывать скачки трафика без проблем.
Использование Adalo и DreamFactory для интеграции унаследованных баз данных
Использование DreamFactory для создания REST API для унаследованных систем
DreamFactory упрощает процесс модернизации унаследованных систем путем преобразования устаревших схем баз данных в полностью документированные REST API. Он автоматически генерирует стандартные конечные точки—GET, POST, PUT и DELETE—делая доступ к данным более эффективным и улучшая производительность запросов.
Его интеллектуальная обработка отношений, включая объединения и подзапросы, устраняет неэффективность, вызванную проблемами N+1 запросов. Такие функции, как пулинг соединений, фильтрация и проекция полей, помогают снизить нагрузку на ресурсоемкие системы, обеспечивая более плавную работу.
«Унаследованные базы данных часто настолько сложны в работе, потому что они кажутся неприступными с первого взгляда, без простого способа извлечения информации внутри. API меняют это, придавая вашим унаследованным системам более дружелюбный, мягкий и знакомый облик.» — Terence Bennett, генеральный директор DreamFactory
Тестирование на $15 Digital Ocean Droplet с 10 запросами MySQL в секунду продемонстрировали эффективность DreamFactory: кеширование снизило время отклика с 2524 мс до всего 101 мс— улучшение на 96%. Кроме того, компании могут сэкономить в среднем $45 719 на один API, оптимизируя развертывание и управление.
DreamFactory предлагает 14-дневный бесплатный пробный период и поддерживает встроенные соединители для баз данных, таких как MS SQL Server, Oracle, IBM DB2и PostgreSQL. Он также включает важные функции, такие как управление доступом на основе ролей, SSO, JWT и шифрование, делая его надежным решением для управления API.
Подключение фронтенд-приложений с Adalo
Adalo, конструктор приложений на базе ИИ, дополняет уровень API DreamFactory, предоставляя инструменты для создания современных пользовательских интерфейсов для систем унаследованных данных. Подключаясь непосредственно к созданным DreamFactory API, Adalo позволяет разработчикам создавать нативные мобильные и веб-приложения без необходимости переработки бэкенда.
Ada, конструктор искусственного интеллекта Adalo, позволяет вам описать то, что вы хотите, и генерирует ваше приложение. Magic Start создает полные основы приложения из описания, а Magic Add добавляет функции на естественном языке.
То, что выделяет Adalo, — это его AI Builder с Magic Start—опишите, что вы хотите создать, и он автоматически генерирует структуру вашей базы данных, экраны и пользовательские потоки. Magic Add позволяет продолжить разработку, просто описав новые функции, которые вам нужны. Такой подход с помощью ИИ означает, что то, что раньше занимало дни планирования, теперь происходит за минуты.
Благодаря подходу с единой кодовой базой платформа позволяет одновременное развертывание в веб, App Store для iOS и Play Store для Android. По цене $36/месяц, Adalo предлагает публикацию в нативных магазинах приложений без ограничений на действия, пользователей, записи или хранилище—прогнозируемое ценообразование без неожиданностей на основе использования. Сравните это с альтернативами, такими как Bubble ($69/месяц с Workload Units) или Thunkable ($189/месяц для публикации в магазинах приложений), и ценность становится очевидной.
Для корпоративных пользователей Adalo Blue (blue.adalo.com) добавляет расширенные функции, такие как SSO, корпоративные разрешения и бесшовная интеграция с системами, у которых отсутствуют API—благодаря DreamFactory. Модульная инфраструктура платформы масштабируется для поддержки приложений с миллионами активных пользователей в месяц, обрабатывая 20 млн+ ежедневных запросов с надежностью 99%+.
Например, National Institutes of Health модернизировала аналитику заявок на гранты, подключив базы данных SQL через API DreamFactory. Аналогично крупная энергетическая компания США преодолела задержки интеграции между Snowflake и унаследованными системами, используя этот подход.
Чтобы оптимизировать производительность, переместите логику на уровень API. Параметры запроса DreamFactory—такие как ?fields, ?related, ?limit, и ?offset—позволяют вам получить только необходимые данные, извлечь вложенную информацию одним объединением и эффективно разбить результаты на страницы. Это снижает время сериализации и устраняет необходимость в нескольких последовательных вызовах.
Эта стратегия интеграции решает распространенную проблему: 90% ИТ-лиц, принимающих решения, говорят, что унаследованные системы препятствуют внедрению ими цифровых инструментов, и 88% лидеров цифровой трансформации видели сбои проектов из-за проблем с унаследованными базами данных. Обернув унаследованные базы данных в REST API и подключив их к современным конструкторам приложений, таким как Adalo, команды могут создать обновленные пользовательские приложения всего за дни или недели—без изменения базовой инфраструктуры.
Заключение: ключевые стратегии для более быстрых времён отклика API
Чтобы повысить производительность API с унаследованными базами данных, сосредоточьтесь на пулинге соединений, исправлении проблем N+1 запросов, стратегическом индексировании и кешировании. Эти методы решают обработку соединений, эффективность запросов и скорость извлечения данных. Начните с пулинга соединений, который может сократить время транзакций на целых 72%. Затем обратитесь к проблемам N+1 запросов используя упреждающую загрузку или пакетную обработку, которые могут снизить время отклика на 45%. Реализация стратегического индексирования может снизить время запроса на 70–85% без изменения вашей кодовой базы.
Кеширование остается игровым изменением. Инструменты, такие как Redis или Memcached, могут облегчить нагрузку на базу данных на 70–90% для API с большим количеством операций чтения. Однако эффективное кеширование требует надежных стратегий инвалидации для балансирования скорости с согласованностью данных. Как сказал Cody Lord из DreamFactory:
«Самый быстрый запрос—это тот, который вы не запускаете.»
Помимо этих шагов, постоянная настройка необходима. По мере роста данных оптимизаторы баз данных могут вести себя по-другому, поэтому регулярный анализ планов выполнения с помощью инструментов, таких как EXPLAIN ANALYZE , имеет решающее значение. Стремитесь к коэффициенту попадания в буфер пула выше 90%, чтобы избежать задержек, вызванных операциями чтения с диска.
Для команд, работающих со старыми системами, сочетание генерации REST API DreamFactory с построением приложений с помощью ИИ Adalo предлагает практический путь вперед. Обернув унаследованные базы данных в REST API и подключив их к современным интерфейсам, вы можете развернуть обновленные приложения за дни или недели вместо месяцев—без изменения базовой инфраструктуры.
Похожие посты в блоге
- 8 способов оптимизировать производительность приложения без кода
- 5 метрик для отслеживания производительности приложений без кода
- 5 советов по снижению задержки запроса базы данных
- REST API и прямой доступ к БД для приложений без кода
Часто задаваемые вопросы
Почему выбрать Adalo вместо других решений для создания приложений?
Adalo—это конструктор приложений на базе ИИ, который создает истинные нативные приложения для iOS и Android из единой кодовой базы. В отличие от веб-обёрток, он компилируется в нативный код и публикуется непосредственно в App Store от Apple и Google Play Store. По цене $36/месяц без ограничений на пользователей, записи или хранилище, он предлагает самое прогнозируемое ценообразование для разработки нативных приложений.
Какой самый быстрый способ создать и опубликовать приложение в App Store?
AI Builder Adalo с Magic Start генерирует полные основы приложений из простого описания—структура базы данных, экраны и пользовательские потоки созданы автоматически. Интерфейс перетаскивания и построение с помощью ИИ позволяют вам перейти от идеи к опубликованному приложению за дни. Adalo обрабатывает сложный процесс отправки в App Store, чтобы вы могли сосредоточиться на функциях вместо сертификатов и профилей подготовки.
Могу ли я легко подключить устаревшую базу данных к современному мобильному приложению?
Да. Используя инструменты, такие как DreamFactory, для генерации REST API из вашей существующей базы данных, вы можете подключить эти API непосредственно к Adalo для создания полированных веб и мобильных интерфейсов без переработки инфраструктуры вашего бэкенда. Этот подход позволяет командам модернизировать пользовательские приложения за дни или недели.
Что вызывает медленные времена отклика API при работе с унаследованными базами данных?
Медленные ответы API с устаревшими базами данных обычно вызваны проблемами N+1 запросов, отсутствующими индексами, неэффективными объединениями и накладными расходами на подключение. Высокая задержка от повторяющихся вызовов базы данных и устаревшей инфраструктуры может привести к увеличению времени ответа с миллисекунд до нескольких секунд, что значительно влияет на пользовательский опыт.
Насколько кэширование может улучшить производительность API?
Кэширование может значительно улучшить производительность API, сокращая время ответа до 96% в некоторых случаях. Инструменты, такие как Redis или Memcached, хранят часто используемые результаты запросов в памяти, что может снизить нагрузку на базу данных на 70–90% для API с интенсивным чтением, одновременно устраняя избыточные вызовы базы данных.
Что такое проблема N+1 запроса и как её решить?
Проблема N+1 запроса возникает, когда API выполняет один запрос для получения списка элементов, а затем выполняет дополнительные запросы для связанных данных каждого элемента. Вы можете исправить это, используя методы быстрой загрузки, которые извлекают все необходимые данные в одну поездку в базу данных, такие как JOIN или пакетная обработка с предложениями WHERE id IN.
Как пулирование соединений помогает производительности API?
Пулирование соединений повторно использует подключения к базе данных вместо создания новых соединений TCP/TLS для каждого запроса API. Это может сократить время транзакций до 72% и особенно полезно в высококонкурентных средах, где повторное установление новых соединений создаёт значительные накладные расходы.
Что более доступно — Adalo или Bubble?
Adalo более доступен по цене $36/месяц по сравнению с $69/месяц Bubble за эквивалентную функциональность. Что ещё более важно, Adalo предлагает неограниченное использование без ограничений на действия, пользователей, записи или хранилище, тогда как Bubble взимает дополнительную плату за единицы рабочей нагрузки на основе использования CPU и операций с базой данных — что делает затраты непредсказуемыми по мере масштабирования приложения.
Сколько времени требуется для создания приложения, которое подключается к устаревшей базе данных?
С помощью DreamFactory, генерирующей REST API из вашей устаревшей базы данных, и AI-ассистированного построения Adalo вы можете создать функциональное приложение за дни, а не месяцы. Magic Start генерирует основу вашего приложения из описания, а Magic Add позволяет создавать новые функции, просто описав, что вам нужно.
Нужен ли опыт кодирования для подключения API к мобильному приложению?
Опыт кодирования не требуется. Визуальный интерфейс Adalo позволяет подключаться к внешним API через конфигурацию наведи-и-щёлкни. DreamFactory автоматически генерирует задокументированные REST-конечные точки из вашей базы данных, а переносимый построитель Adalo решает проблемы фронтенда — знание программирования не требуется.
Быстро создавайте приложение с помощью одного из наших готовых шаблонов приложений
Начните создавать без кодаСвязанный контент

Решение проблем производительности в устаревших API
Снизьте задержку устаревшего API с помощью кэширования, настройки запросов, оборачивания API и постепенной миграции микросервисов — практические быстрые победы и долгосрочные решения.

5 советов по снижению задержки запроса базы данных
Сократьте задержки запросов с помощью индексирования, эффективного SQL, кэширования, секционирования и анализа плана выполнения для ускорения баз данных и снижения затрат.

DreamFactory: упростите подключения API базы данных
Автоматически генерируйте защищенные REST API для 20+ баз данных, обрабатывайте RBAC, JWT, документы OpenAPI и подключайте унаследованные системы к приложениям без пользовательского кода

Синхронизация ERP в реальном времени с унаследованными системами
Подключите устаревшие ERP к современным приложениям с синхронизацией в реальном времени, используя API, вебхуки или CDC для устранения задержек, снижения ошибок и поддержания существующих сист