
Медленные запросы к базе данных незаметно снижают производительность вашего приложения, разочаровывают пользователей и увеличивают затраты на инфраструктуру. Эти пять проверенных методов помогут вам устранить узкие места задержек и обеспечить быстрый и отзывчивый опыт, который ожидают ваши пользователи.
Один из подходов, упрощающих оптимизацию базы данных, — это разработка с помощью Adalo, конструктора приложений без кода для веб-приложений и нативных приложений iOS и Android, работающих на одной версии на всех трех платформах и опубликованных в Apple App Store и Google Play. Встроенная база данных Adalo обеспечивает нулевую задержку API, а инфраструктура автоматически справляется с кешированием и оптимизацией запросов, так что вы можете сосредоточиться на приложении вместо ручной настройки базы данных.
Независимо от того, оптимизируете ли вы существующую систему или запускаете новый MVP, быстрый выход приложения в магазины приложений означает достижение максимально широкой аудитории с помощью push-уведомлений и нативной производительности. Вот как сделать запросы к базе данных молниеносно быстрыми.
Задержка запросов к базе данных может снизить производительность вашего приложения, разочаровать пользователей и увеличить затраты. Независимо от того, создаете ли вы простой внутренний инструмент или приложение, обращенное к клиентам, с тысячами пользователей, медленные запросы создают узкие места, которые распространяются по всей системе. Вот как это исправить:
- Индексирование: используйте индексы для ускорения извлечения данных путем нацеливания на столбцы в
WHERE,JOIN, иORDER BYпредложениях. Избегайте чрезмерного индексирования, чтобы предотвратить замедление операций записи. - Эффективные запросы: избегайте
SELECT *, оптимизируйтеWHEREусловия для использования индекса и минимизируйте ненужные объединения или подзапросы. - Кэширование: сохраняйте часто используемые данные в памяти с помощью инструментов вроде Redis или Memcached для снижения нагрузки на базу данных. Используйте
TTLдля поддержания свежести кешированных данных. - Секционирование: разделите большие таблицы на меньшие части или синхронизируйте данные между платформами (горизонтальное или вертикальное) для повышения производительности запросов на массивных наборах данных.
- Планы выполнения запросов: проанализируйте планы выполнения, чтобы определить узкие места, такие как последовательные сканирования или пролитие на диск. Соответственно настройте индексы и структуры запросов.
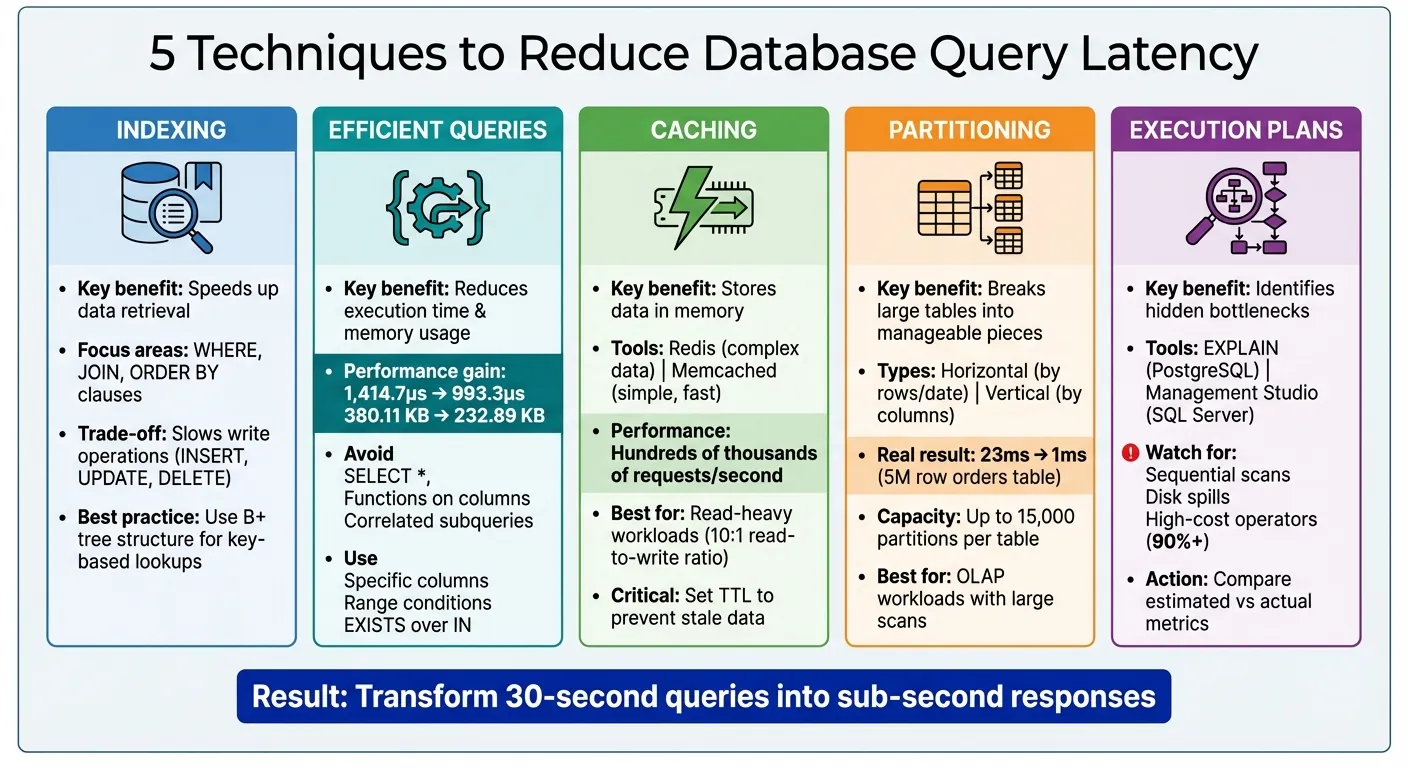
Оптимизация задержки запросов к базе данных: сравнение 5 ключевых методов
Почему мои запросы к базе данных выполняются так медленно? - Next LVL Programming
1. Использование индексирования базы данных
Думайте об индексах базы данных как об указателе в конце книги — они служат ярлычками, указывающими прямо на нужные вам строки в таблице. Это позволяет ядру базы данных не сканировать каждую строку, что делает извлечение данных намного быстрее. Большинство индексов основаны на структуре B+ дерева, которая разработана для быстрого поиска по ключам. Правильное настройка индексирования — ключевой этап оптимизации запросов к базе данных, особенно при оценке вариантов интеграции базы данных для вашего приложения.
Сосредоточьтесь на индексировании столбцов, которые часто используются в WHERE, JOIN, и ORDER BY предложениях — это может привести к заметному улучшению производительности запросов. Например, покрывающий индекс может выбрать все необходимые столбцы напрямую, уменьшив ненужные операции ввода-вывода.
Для более простых запросов часто достаточно одноколоночных индексов. Однако для запросов с несколькими условиями составные индексы — это то, что вам нужно. При создании составных индексов стратегически расположите столбцы: начните с фильтров равенства, затем добавьте фильтры диапазона и рассмотрите уникальность столбцов.
Хотя индексы ускоряют SELECT операции, они имеют компромисс — они могут замедлить операции записи, такие как INSERT, UPDATE, и DELETE. Чтобы избежать ненужных затрат, следите за использованием индексов и удаляйте те, которые не добавляют ценности.
«Распространенной ошибкой проектирования является создание множества индексов в спекулятивных целях, чтобы «дать оптимизатору возможности выбора». Результирующее чрезмерное индексирование замедляет изменение данных и может вызвать проблемы с одновременностью». - Руководство по проектированию индексов Microsoft SQL Server
Лучшие практики индексирования
При внедрении индексов учитывайте эти рекомендации:
- Первичные ключи автоматически индексируются в большинстве систем баз данных
- Внешние ключи используемые в объединениях, значительно выигрывают от индексирования
- Столбцы с высокой кардинальностью (много уникальных значений) — лучшие кандидаты для индекса, чем столбцы с несколькими различными значениями
- Регулярно проверяйте ваши индексы, чтобы найти неиспользуемые, которые только добавляют нагрузку на запись
Adalo — это конструктор приложений без кода для веб-приложений и нативных приложений iOS и Android, работающих на одной версии на всех трех платформах и опубликованных в Apple App Store и Google Play. Современные конструкторы приложений на основе ИИ, такие как Adalo, автоматически справляются с большей частью этой сложности. С модернизацией инфраструктуры платформы в 2026 году операции с базой данных работают в 3-4 раза быстрее чем раньше, и система масштабирует инфраструктуру в соответствии с потребностями приложения — это означает, что нет ограничений на записи в платных планах. Это избавляет от необходимости вручную оптимизировать индексы для большинства распространенных случаев использования.
2. Написание более эффективных запросов
То, как вы структурируете запрос, может обеспечить или сорвать его производительность. Для начала избегайте использования SELECT *. Вместо этого указывайте только те столбцы, которые вам действительно нужны. Например, если вы работаете с базу данных клиентов и вам нужны только ID, имя и адрес электронной почты, запросите только эти три поля. Выборка ненужных столбцов расходует память и пропускную способность.
Структура запроса имеет такое же значение, как и индексирование. Использование полной выборки сущностей в ORM (Object-Relational Mappers) может добавить значительные издержки. Тест производительности показал, что переход на запросы без отслеживания сократил время выполнения с 1414,7 микросекунд до 993,3 микросекунд и снизил использование памяти с 380,11 КБ до 232,89 КБ. Чтобы избежать этих издержек, используйте проекции в вашем ORM — методы, такие как .Select() в EF Core или .values() в Django— для получения только необходимых полей.
Оптимизация условий WHERE
При оптимизации условий WHERE обращайте внимание на то, как их записать. Функции на столбцах, такие как WHERE YEAR(hire_date) = 2020, препятствуют эффективному использованию индексов. Вместо этого используйте условия на основе диапазонов, такие как WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01'. Этот подход сохраняет «SARG-ability» (поддержку поиска по аргументам), позволяя запросу использовать индексы. Аналогично избегайте шаблонов с подстановочными знаками в начале в LIKE запросах, так как они вынуждают выполнять полное сканирование таблицы.
«Главный решающий фактор того, будет ли запрос выполняться быстро или нет, — это будет ли он правильно использовать индексы где это необходимо».
– Документация Microsoft
Сокращение соединений и подзапросов
Уменьшайте использование ненужных соединений и подзапросов. Коррелированные подзапросы — те, которые зависят от внешнего запроса, — особенно проблематичны, так как они выполняются один раз для каждой строки в наборе результатов. Вместо этого, когда это возможно, замените их стандартными соединениями. Если вы проверяете наличие данных, используйте EXISTS вместо IN. Платформа EXISTS условие останавливает обработку, как только находит совпадение, что намного эффективнее.
По словам Майка Пейна, эксперта по базам данных: «Оптимизация этих запросов — это единственное наиболее действенное, что вы можете сделать для повышения скорости и масштабируемости вашей базы данных».
Ada, конструктор искусственного интеллекта Adalo, позволяет вам описать то, что вы хотите, и генерирует ваше приложение. Magic Start создает полные основы приложения из описания, а Magic Add добавляет функции на естественном языке.
Для тех, кто создает приложения без прямого написания SQL, визуальный интерфейс Adalo абстрагирует эти оптимизации. Функции платформы с поддержкой ИИ, такие как Волшебное добавление , позволяют описать необходимые вам данные на естественном языке, и система автоматически генерирует эффективные запросы. Это особенно ценно для нетехнических разработчиков, которые хотят повышения производительности без погружения в оптимизацию запросов.
3. Кеширование часто используемых запросов
Кеширование — это как дать вашему приложению ускорение памяти. Вместо многократного запроса к базе данных часто используемые данные хранятся в памяти, что сокращает время получения информации. Это избегает задержек, связанных с доступом к диску, которые — даже в лучшем случае — могут занимать десятки миллисекунд.
Два популярных инструмента для кеширования — Redis и Memcached. Redis выделяется своей способностью обрабатывать сложные структуры данных и опцией постоянства на диске. С другой стороны, Memcached проще и легче, разработан исключительно для высокоскоростного кеширования. Чтобы дать вам представление об их возможностях, один узел кеша в памяти может обрабатывать сотни тысяч запросов в секунду.
Паттерн Cache-Aside
Наиболее распространенный метод кеширования — cache-aside, также называется ленивой загрузкой. Вот как это работает: приложение сначала проверяет кеш. Если данных там нет («промах»), оно запрашивает базу данных, получает данные и затем обновляет кеш. Этот метод особенно эффективен в сценариях с интенсивным чтением, где данные читаются по крайней мере в 10 раз чаще, чем записываются. Объединяя эту стратегию с методами оптимизации запросов из предыдущего раздела, вы можете значительно снизить нагрузку на вашу базу данных.
Чтобы предотвратить задержку устаревших данных, всегда устанавливайте TTL (время жизни) для ваших кэшированных данных. Если вы работаете с Redis, рассмотрите возможность использования Hashes для хранения строк базы данных. Этот подход позволяет обновлять отдельные поля без необходимости обработки целого JSON-объекта. Кроме того, следите за своим коэффициентом попадания кеша— низкий коэффициент означает, что ваш кеш используется неэффективно, что расходует память без облегчения нагрузки на базу данных.
«Скорость и пропускная способность вашей базы данных могут быть наиболее действенным фактором для общей производительности приложения». – AWS
Когда внедрять кеширование
Не каждому приложению нужен отдельный слой кеширования. Рассмотрите возможность внедрения кеширования в следующих случаях:
- Запросы к вашей базе данных постоянно медленные, несмотря на оптимизацию
- Одни и те же данные запрашиваются несколько раз разными пользователями
- Ваше приложение испытывает всплески трафика, которые перегружают базу данных
- Операции чтения значительно превышают операции записи
Модульная инфраструктура Adalo обрабатывает кеширование на уровне платформы, что означает, что приложения, построенные на платформе, получают выгоду от оптимизированного получения данных без ручной настройки кеша. Система обрабатывает Прямая публикация в App Store с 99%+ временем доступности, демонстрируя эффективность встроенных оптимизаций производительности.
4. Разделение больших наборов данных
Когда таблицы разрастаются до миллионов строк, даже лучше всего индексированные запросы могут начать замедляться. Секционирование предлагает способ решить эту проблему, разбивая большие таблицы на меньшие, более управляемые части — называемые партициями — при этом продолжая обращаться к ним как к единой логической таблице. Это позволяет ядру базы данных использовать исключение партиций, которое пропускает нерелевантные партиции во время запроса, значительно сокращая объем данных, которые необходимо сканировать. Ключ в том, чтобы выбрать правильный метод разделения данных для обеспечения эффективного сканирования.
Горизонтальное и вертикальное разделение
Существует два основных способа разделения данных: горизонтальное разделение и вертикальное разделение.
- Горизонтальное разделение разделяет таблицу по строкам, часто на основе определенного столбца, такого как дата или регион. Например, можно разделить таблицу продаж на ежемесячные куски. Этот метод особенно хорошо работает для временных рядов или сценариев, в которых запросы часто фильтруют по определенному диапазону.
- Вертикальное разделение, с другой стороны, разделяет столбцы. Это идеально подходит для широких таблиц с множеством полей, особенно если обычно обращаются только к нескольким столбцам. Например, можно перенести большие BLOB-объекты или редко используемые поля в отдельные таблицы.
Вот пример из реальной жизни: разделение таблицы заказов объемом 5 000 000 строк в Airtable по месяцам сократило время запроса с 23 мс до всего 1 мс. Современные ядра баз данных, такие как SQL Server, могут обрабатывать до 15 000 партиций на таблицу. Однако важно не переусложнять —чрезмерное разделение может привести к увеличению использования памяти и снижению производительности, если запросы заканчивают сканирование нескольких партиций.
| Тип разделения | Метод | Лучше всего подходит для |
|---|---|---|
| Горизонтальное | Разделяет строки (например, по дате или диапазону ID) | Большие наборы данных с запросами на основе диапазонов |
| Вертикальное | Разделяет столбцы (например, отделяя BLOB-объекты от часто обращаемых полей) | Широкие таблицы, где обычно запрашиваются только несколько столбцов |
Выбор правильного ключа разделения
Чтобы разделение работало эффективно, выберите столбец, который часто используется в предложениях WHERE. Это обеспечивает полное использование базой данных исключения партиций. Кроме того, согласуйте индексы со схемой разделения, чтобы улучшить задачи обслуживания. Разделение особенно хорошо подходит для рабочих нагрузок OLAP, которые включают большие сканирования, а не для систем OLTP, где запросы обычно извлекают отдельные строки.
Для разработчиков приложений, работающих с большими наборами данных, инфраструктура Adalo теперь масштабируется в соответствии с потребностями приложения — нет верхнего предела количества записей в базе данных для платных планов. При правильной настройке связей данных приложения, созданные на этой платформе, могут масштабироваться за пределы 1 миллионом активных пользователей в месяц. Это исключает необходимость в стратегиях ручного разделения, которые требуют другие платформы с ограничениями на количество записей.
5. Проверьте планы выполнения запросов
После того как вы разобрались с индексированием и рефакторингом запросов, анализ планов выполнения может дать более глубокое понимание производительности запросов. Даже хорошо оптимизированные запросы могут столкнуться с непредвиденными узкими местами, и планы выполнения помогают выявить, как база данных обрабатывает запрос. Они содержат информацию об использовании индексов, методах объединения и операциях сортировки.
Использование EXPLAIN и инструментов плана выполнения
В PostgreSQL, инструменты вроде EXPLAIN и EXPLAIN ANALYZE бесценны. EXPLAIN предоставляет предполагаемые затраты, тогда как EXPLAIN ANALYZE добавляет фактические метрики производительности, такие как количество строк и время выполнения. Сравнивая их, можно заметить расхождения, которые могут указывать на устаревшую статистику или неоптимальное индексирование. Аналогично, планы фактического выполнения SQL Server в Management Studio предоставляют сравнимые insights. Эти инструменты помогают выявить неэффективность, которая может быть не очевидна при использовании других методов оптимизации.
На что обратить внимание
При анализе плана выполнения обратите внимание на закономерности типа «Sequential Scan» на больших таблицах. Это часто указывает на то, что добавление индекса может улучшить производительность. Также ищите условия фильтрации, которые отбрасывают большинство строк после сканирования, так как они могут выиграть от преобразования в операцию «Index Cond». Еще одним красным флагом является операция сортировки или хеширования, переполняющаяся на диск, что может значительно увеличить задержку запроса. Сравнение времени CPU с прошедшим временем также может выявить, ограничен ли запрос использованием CPU или ожидает операций ввода-вывода.
Если отдельный оператор, такой как «Sort» или «Hash Join», составляет 90% стоимости запроса, это явная цель для оптимизации. Можно также экспериментировать с временным отключением определенных опций планировщика, чтобы протестировать альтернативные стратегии объединения и посмотреть, дают ли они лучшую производительность на практике. Обратите внимание на предупреждения о неявных преобразованиях типов данных, так как они могут заставить ядро обрабатывать каждую строку отдельно, снижая эффективность индексов.
Автоматический анализ производительности
Для тех, кто предпочитает не анализировать планы выполнения вручную, Adalo предлагает X-Ray— функцию искусственного интеллекта, которая выявляет проблемы производительности до того, как они повлияют на пользователей. Такой упреждающий подход к мониторингу производительности позволяет выявлять и устранять узкие места без погружения во внутреннюю структуру базы данных. Функция выделяет потенциальные проблемы масштабируемости и предлагает оптимизацию, что особенно ценно для нетехнических разработчиков, масштабирующих свои приложения.
Сравнение подходов к базам данных для разработчиков приложений
При выборе платформы для создания приложений производительность и масштабируемость базы данных должны быть основными критериями. Различные платформы по-разному обрабатывают хранение данных и оптимизацию запросов.
| Платформа | Подход к базе данных | Ограничения записей | Начальная цена |
|---|---|---|---|
| Adalo | Встроенная + внешние подключения | Неограниченно в платных планах | $36/месяц |
| Bubble | Встроенная с единицами рабочей нагрузки | Ограничено расчетами рабочей нагрузки | $69/месяц |
| Glide | На основе электронной таблицы | Ограниченно, применяются дополнительные платежи | $60/месяц |
| FlutterFlow | Только внешние (управляются пользователем) | Зависит от внешнего провайдера | $70/месяц + затраты на базу данных |
Bubble предлагает больше опций настройки, но эта гибкость часто приводит к более медленным приложениям, которые страдают при увеличении нагрузки. Многие пользователи Bubble в итоге нанимают экспертов для оптимизации своих приложений — заявления о миллионах MAU обычно достижимы только с профессиональной помощью. Решение Bubble для мобильных приложений также является оберткой для веб-приложения, создавая потенциальные проблемы при масштабировании.
FlutterFlow технически является "low-code" скорее, чем "no-code" и ориентирован на технических пользователей. Пользователи должны устанавливать и управлять собственной внешней базой данных, что требует значительной сложности обучения. Любая конфигурация менее оптимальной может создать проблемы масштабирования, поэтому экосистема FlutterFlow богата платными экспертами.
Glide превосходит в создании приложений на основе электронных таблиц, но создает универсальные, упрощенные приложения с ограниченной творческой свободой. Он не поддерживает публикацию в Apple App Store или Google Play Store, ограничивая варианты распределения.
Заключение
Снижение задержки запросов к базе данных — это все о повышении скорости и обеспечении масштабируемости. Такие методы, как индексирование, написание эффективных запросов, кеширование, секционирование и проверка планов выполнения, могут превратить медленные запросы за 30 секунд в молниеносные ответы менее чем за секунду.
Но преимущества выходят за пределы просто скорости. Оптимизированные запросы означают, что меньше ресурсов сервера потребляется, что может снизить ежемесячные затраты и обеспечить более гладкий опыт по мере роста базы пользователей. Эффективные запросы также помогают снизить нагрузку на сервер и избежать достижения ограничений частоты API, таких как Airtableограничение 5 запросов в секунду. Небольшие настройки сейчас могут сэкономить вам от больших головных болей в дальнейшем.
Adalo, конструктор приложений на базе ИИ, упрощает эту оптимизацию благодаря своему визуальному интерфейсу и интегрированному серверу. Для приложений с меньшими наборами данных встроенная база данных Adalo обеспечивает нулевую задержку API с быстрой производительностью. Нужно масштабировать или работать совместно? Вы можете подключиться к внешним базам данных, таким как Airtable, PostgreSQL или MS SQL Server, используя External Collections, доступные на плане Professional начиная с $36 в месяц. Эта гибкость позволяет вам начать с простой настройки и масштабироваться по мере необходимости без переделки приложения.
Чтобы начать, сосредоточьтесь на профилировании ваших самых медленных запросов с помощью инструментов, таких как EXPLAIN и сначала решите наиболее серьезные узкие места. Независимо от того, добавляете ли вы индекс или настраиваете уровень кеширования, каждое улучшение строится на предыдущем. Как мудро отмечает Майк Пейн из Paessler :
Вы не можете оптимизировать то, что не видите. Мониторинг базы данных освещает ровно там, где находятся проблемы производительности.
Как только вы определили проблемные области, исправления часто просты и дают немедленные результаты.
Похожие посты в блоге
- 8 способов оптимизировать производительность приложения без кода
- Как создать приложение с использованием данных IBM DB2
- 5 метрик для отслеживания производительности приложений без кода
- Масштабирование приложений без кода для больших наборов данных
Часто задаваемые вопросы
Почему выбрать Adalo вместо других решений для создания приложений?
Adalo — это приложение для создания приложений на базе ИИ, которое создает истинные нативные приложения для iOS и Android. В отличие от веб-оболочек, оно компилируется в нативный код и публикуется напрямую в Apple App Store и Google Play Store из единой кодовой базы — самая сложная часть запуска приложения выполняется автоматически.
Какой самый быстрый способ создать и опубликовать приложение в App Store?
Интерфейс Adalo с перетаскиванием в сочетании с помощью ИИ при создании приложений через Magic Start и Magic Add позволяет вам создавать полные приложения за часы вместо недель. Платформа справляется со всем процессом отправки в App Store, устраняя технические барьеры, которые обычно замедляют запуск приложений.
Могу ли я легко оптимизировать запросы к базе данных в моем приложении?
Да, с визуальным интерфейсом Adalo и интегрированным сервером вы можете оптимизировать производительность базы данных без написания SQL. Для приложений с меньшими наборами данных встроенная база данных Adalo обеспечивает нулевую задержку API, и вы можете подключиться к внешним базам данных, таким как PostgreSQL или Airtable, для больших наборов данных, используя External Collections.
Какой наиболее эффективный способ снизить задержку запросов к базе данных?
Правильное индексирование базы данных часто является наиболее эффективным первым шагом, так как индексы действуют как ярлыки, которые указывают непосредственно на нужные строки вместо сканирования всех таблиц. Сосредоточьтесь на индексировании столбцов, обычно используемых в предложениях WHERE, JOIN и ORDER BY, для лучшего улучшения производительности.
Когда мне использовать кеширование в сравнении с секционированием для больших наборов данных?
Используйте кеширование, когда у вас есть часто используемые данные, которые не меняются часто — инструменты, такие как Redis или Memcached, могут обрабатывать сотни тысяч запросов в секунду. Используйте секционирование, когда ваши таблицы растут до миллионов строк и запросы фильтруются по определенным диапазонам, таким как даты, так как это позволяет базе данных полностью пропустить неуместные данные.
Как я могу определить, какие запросы вызывают проблемы производительности?
Используйте инструменты плана выполнения запроса, такие как EXPLAIN в PostgreSQL или фактические планы выполнения в SQL Server, чтобы увидеть ровно как база данных обрабатывает ваши запросы. Adalo также предлагает X-Ray, функцию ИИ, которая определяет проблемы производительности до того, как они повлияют на пользователей.
Почему я должен избегать использования SELECT * в моих запросах к базе данных?
Использование SELECT * извлекает все столбцы из таблицы, тратя память и полосу пропускания, когда вам нужны только определенные поля. Указание только нужных столбцов может значительно снизить время выполнения и использование памяти — тесты производительности показывают, что переключение на целевые запросы может снизить потребление памяти почти на 40%.
Что более доступно — Adalo или Bubble?
Adalo начинается с $36/месяц с неограниченным использованием и без ограничений по количеству записей на платных планах. Bubble начинается с $69/месяц с платежами на основе использования Workload Units и ограничениями по записям. Adalo также включает неограниченные обновления приложений после публикации, в то время как Bubble имеет ограничения на переопубликацию.
Adalo лучше, чем FlutterFlow для мобильных приложений?
Для нетехнических пользователей — да. FlutterFlow является "low-code" и ориентирован на технических пользователей, которые должны устанавливать и управлять собственной внешней базой данных. Adalo включает встроенную базу данных без ограничений по записям на платных планах, и его визуальный конструктор описывается как "простой как PowerPoint", при этом создавая нативные приложения iOS и Android.
Имеет ли Adalo ограничения по записям базы данных?
Нет. Платные планы имеют неограниченные записи в базе данных без ограничений. При правильной настройке отношений данных приложения Adalo могут масштабироваться сверх 1 миллиона ежемесячно активных пользователей. Модульная инфраструктура платформы автоматически масштабируется в зависимости от потребностей вашего приложения.
Быстро создавайте приложение с помощью одного из наших готовых шаблонов приложений
Начните создавать без кодаСвязанный контент

Улучшение времени отклика API с помощью устаревших баз данных
Ускорьте API с использованием устаревших баз данных с помощью настройки запросов, индексирования, кэширования, пулирования соединений и исправления N+1 запросов для снижения задержки.

Решение проблем производительности в устаревших API
Снизьте задержку устаревшего API с помощью кэширования, настройки запросов, оборачивания API и постепенной миграции микросервисов — практические быстрые победы и долгосрочные решения.

Как ИИ и микроприложения готовы изменить корпоративный рабочий процесс
Микроприложения на основе ИИ автоматизируют повторяющиеся задачи, модернизируют устаревшие системы и обеспечивают создание приложений без кода для ускорения рабочих процессов, снижения затрат и

Будущее SaaS: автоматизация рабочих процессов на основе ИИ
Как SaaS с приоритетом на ИИ использует автономные агенты, рабочие процессы на естественном языке и предсказательную оптимизацию для ускорения процессов, снижения затрат и интеграции